As part of a school project we attempted to replicate the work of Howes and Solomon in 1951. We were interested not only in the words lengths' effect on recognition, but also on the words' context popularity.
We believe that words are easier to recognize not mainly by their length, but by the frequency of which they appear in our everyday vocabulary. Previous research performed in 1951 included only the available database of the word-frequency count from the work of Thorndike-Lorge Teacher’s Word book of 30, 000 words (Kucera and Francis). However, today's databases include the English Lexicon Project with over 4 million English word trials (SUBTLEXus).
Using a small sample of nine students from the University of Carleton, a mix of native and nonnative English speakers, a replica of the Howes and Solomon’s (1951) test was designed, using the PsychoPy program to emulate the functionality of a modern day tachistoscope.
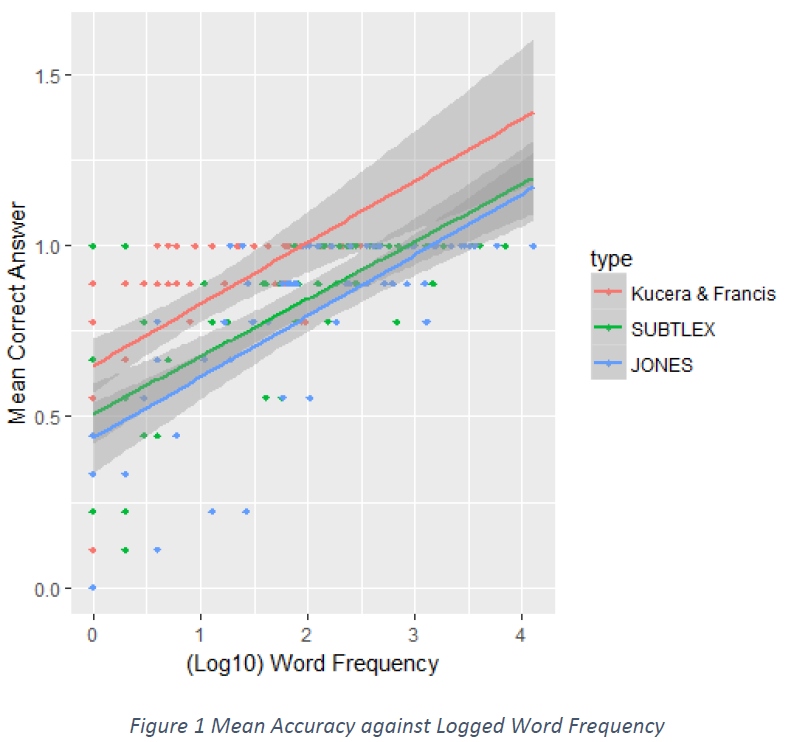
On our first analysis, a correlation test in Figure 1, we discover a stronger positive correlation in accuracy to the SUBTLEXus of 0.7259 as than the one obtained by Kucera & Francis of 0.5956, confirming the effort from Brysbaert and New of creating a more reliable updated database.
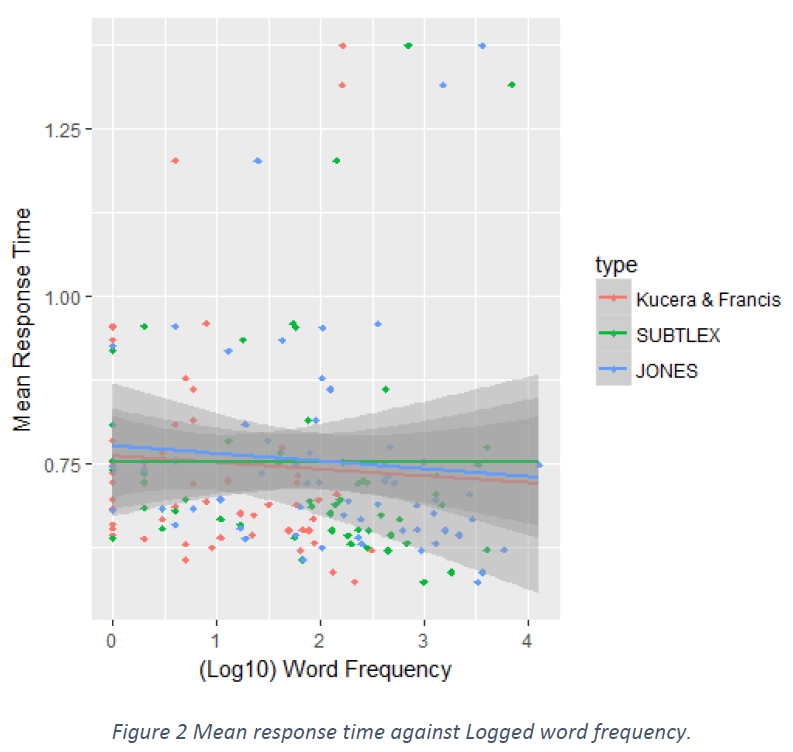
Contrary to our predictions Kucera and Francis’ word frequency Figure 2 showed a stronger negative correlation while SUBTLEXus showed less correlation than expected. SUBTLEXus correlation coefficient measured -0.1868 against the -0.2633 of Kucera and Francis.
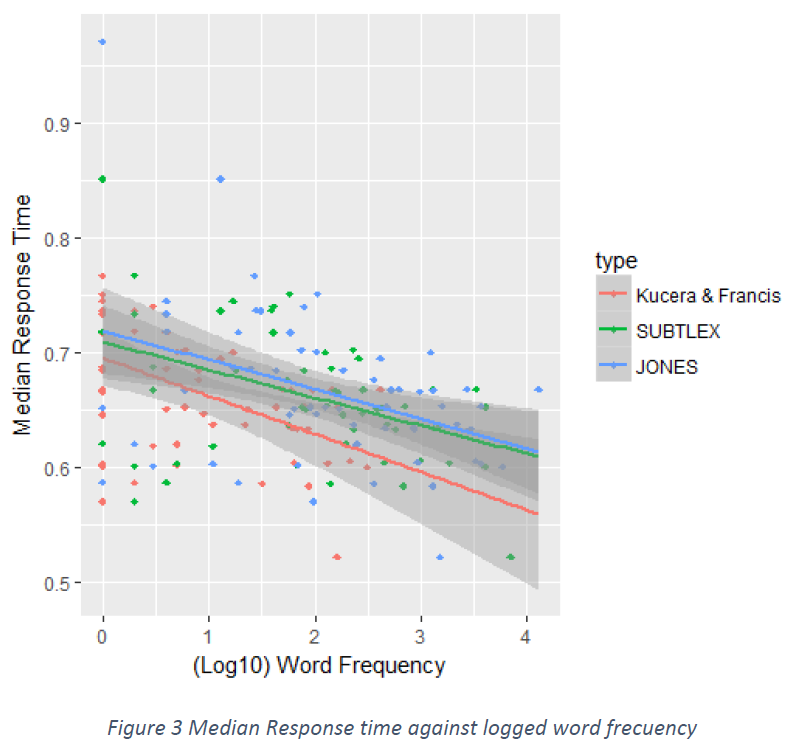
Finally, we felt with such variable responses and with the possibility of outliers a median per group could give us a more insightful result than the calculated mean. In Figure 3 we compared the median of each word group to the logged frequency of both databases, in an effort to correct for the variability in the data presented in Figure 2.
Overall the results from the experiments were contradictory to our predictions, Kucera and Francis database obtained stronger correlations in most comparisons, suggesting the outdated database to be better at predicting word processing than the more contemporary and vastly bigger SUBTLEXus database.
Most of these incorrect findings could be the product of a small sample size, we should also consider words that have been mislabeled and their effect on response time, instead of accepting response times regardless of their correct or incorrect labeling.
If you are interested in this research, you can download our full work here.